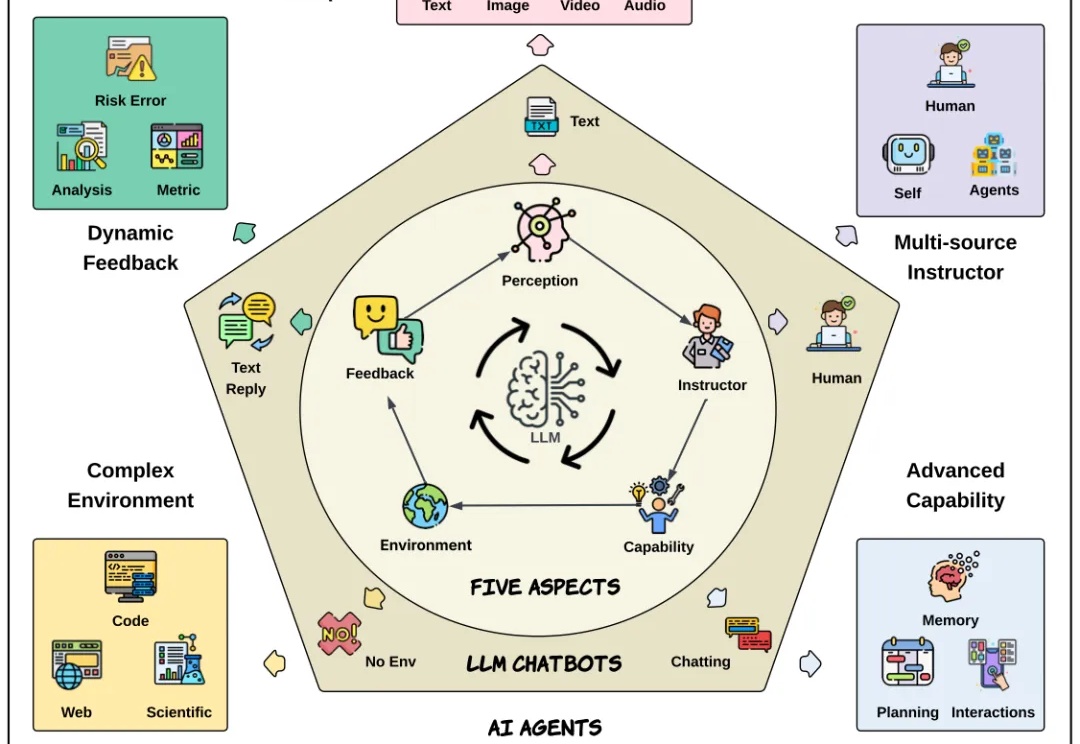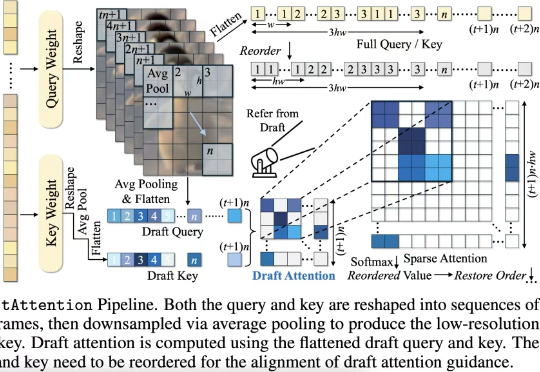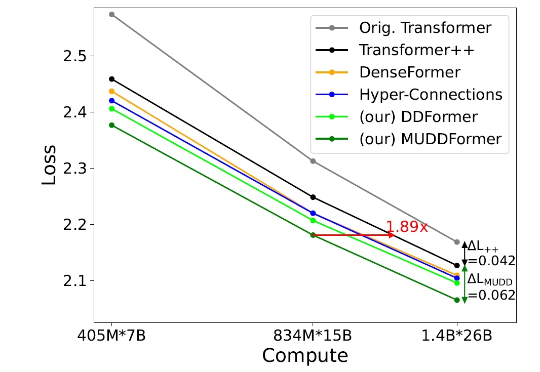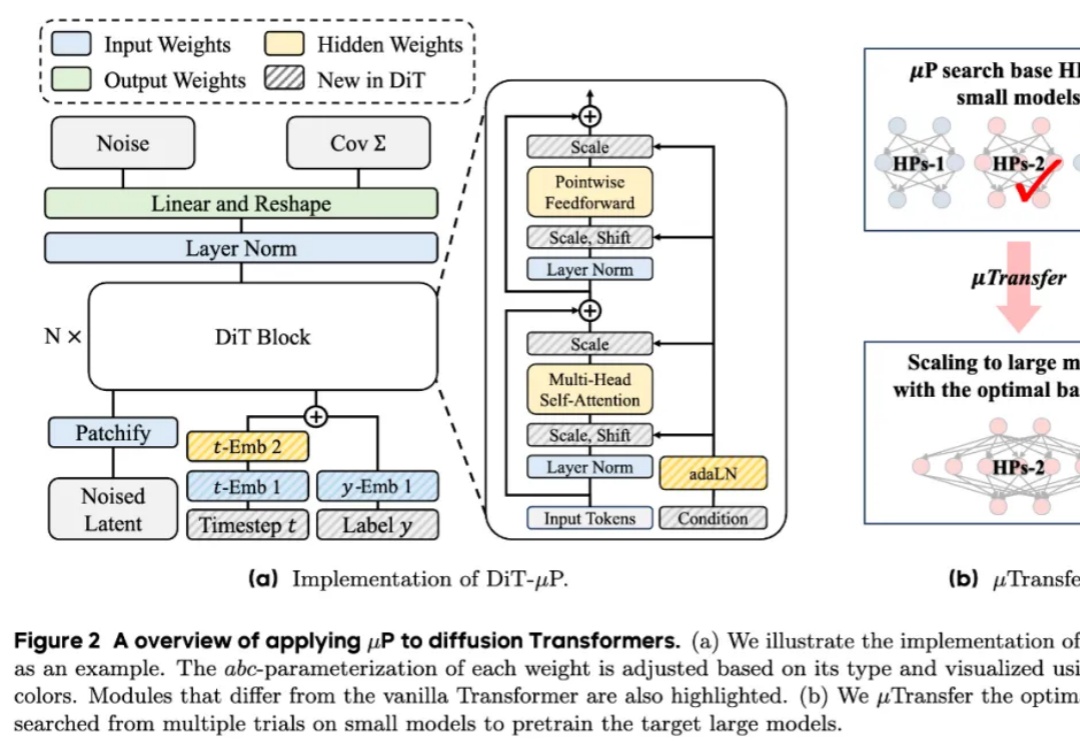
原来Scaling Law还能被优化?Meta这招省token又提效
原来Scaling Law还能被优化?Meta这招省token又提效2017 年,一篇《Attention Is All You Need》论文成为 AI 发展的一个重要分水岭,其中提出的 Transformer 依然是现今主流语言模型的基础范式。尤其是在基于 Transformer 的语言模型的 Scaling Law 得到实验验证后,AI 领域的发展更是进入了快车道。
来自主题: AI技术研报
7958 点击 2025-07-06 14:56